Testing Data with Great Expectations
Read time: 6 minutes
Why#
Data Validation#
If you use python, I hope you use some tool to help you validate and test the code you are writing, for example pytest, or pylint.
But we should also test validity of the data.
For example, missing values could be very problematic for some models, so it’s better to recognize errors in our dataset before we load them into a model (or even before we start pre-processing)
How#
Enter Great Expectations .
I don’t know how people managed data validation and testing before - my guess would be writing lots of assert python code.
Thanks Kyle! And thank you and the team for building and maintaining it. You don't want to know how I managed my data expectations before Great Expectations (involved a lot of duct tape).
— Goku Mohandas (@GokuMohandas) March 9, 2021
Goku, I want to know how did people managed data validation!
I heard people many times mention this tool, but was kind of intimidated and expected something complex, but this is far from the truth. It’s really easy to use.
For my simple project following along Getting started tutorial
was enough.
To start you need to install it.
For me it was:
poetry add great_expectations
Then you can init your project.
great_expectations init
After that you’ll be prompted to configure Datasource. At first I ignored this step. Don’t worry, just run init again, and then you can complete this configuration.
To build intuition about Greater Expectations I followed Made with ML tutorial .
Just create a Jupyter Notebook for prototyping.
I had my dataset loaded in pandas DataFrame.
You need to wrap it load it into PandasDataset.
Both lines of code below produce the same result.
ge_df = ge.dataset.PandasDataset(df)
ge_df = ge.from_pandas(df)
Then you are ready to create expectations.
Expectations#
To quickly create some expectations about my dataset, I used pre-bulid ones.
Here you can find a list of them:
https://docs.greatexpectations.io/en/latest/reference/glossary_of_expectations.html
Of course, you could build a custom one if needed.
Here what I come up with on the spot. They should be self-explanatory.
ge_df.expect_column_to_exist(column="id")
ge_df.expect_column_to_exist(column="full_text")
ge_df.expect_column_values_to_be_unique(column="id")
ge_df.expect_column_values_to_not_be_null(column="full_text")
ge_df.expect_column_values_to_be_of_type(column="id", type_="int")
ge_df.expect_column_values_to_be_of_type(column="full_text", type_="str")
When you have your expectations, you need to group them into expectations suite.
Expectation Suite#
This code will take expectations attached to ge_df and create a suite.
expectation_suite = ge_df.get_expectation_suite()
We can use it later to validate dataset.
print(ge_df.validate(expectation_suite=expectation_suite, only_return_failures=True))
{
"results": [],
"statistics": {
"evaluated_expectations": 6,
"successful_expectations": 6,
"unsuccessful_expectations": 0,
"success_percent": 100.0
},
"meta": {
"great_expectations_version": "0.13.19",
"expectation_suite_name": "default",
"run_id": {
"run_name": null,
"run_time": "2021-05-10T13:10:19.926456+00:00"
},
"batch_kwargs": {
"ge_batch_id": "303d04fa-b190-11eb-9fda-74d43587be13"
},
"batch_markers": {},
"batch_parameters": {},
"validation_time": "20210510T131019.926363Z"
},
"evaluation_parameters": {},
"success": true
}
Using Great Expectations CLI#
So let’s go back to configuring Datasource.
Run great_expectations init again, and CLI will guide you through.
================================================================================
Would you like to configure a Datasource? [Y/n]: Y
What data would you like Great Expectations to connect to?
1. Files on a filesystem (for processing with Pandas or Spark)
2. Relational database (SQL)
: 1
What are you processing your files with?
1. Pandas
2. PySpark
: 1
Enter the path (relative or absolute) of the root directory where the data files are stored.
: data
Give your new Datasource a short name.
[data__dir]: datasources
Great Expectations will now add a new Datasource 'datasources' to your deployment, by adding this entry to your great_expectations.yml:
datasources:
data_asset_type:
class_name: PandasDataset
module_name: great_expectations.dataset
batch_kwargs_generators:
subdir_reader:
class_name: SubdirReaderBatchKwargsGenerator
base_directory: ../data
class_name: PandasDatasource
module_name: great_expectations.datasource
Would you like to proceed? [Y/n]: y
My dataset is in .json format, but GE will load it into Pandas, without me needing to do anything.
Profiling#
Here is where the magic happens:
While prototyping, I had to come up with my own expectations. GE can do this for you.
================================================================================
Would you like to profile new Expectations for a single data asset within your new Datasource? [Y/n]: Y
Would you like to:
1. choose from a list of data assets in this datasource
2. enter the path of a data file
: 1
Which data would you like to use?
1. seen (file)
2. batch_to_add (file)
3. dataset (file)
Don't see the name of the data asset in the list above? Just type it
: 3
Name the new Expectation Suite [dataset.warning]: datasetjson
Great Expectations will choose a couple of columns and generate expectations about them
to demonstrate some examples of assertions you can make about your data.
Great Expectations will store these expectations in a new Expectation Suite 'datasetjson' here:
file:///home/gsajko/work/tweetfeed/great_expectations/expectations/datasetjson.json
Would you like to proceed? [Y/n]: y
Generating example Expectation Suite...
Done generating example Expectation Suite
With this, I have generated automatically expectations for my
dataset.
I come up with 6 of them, GE generated 16.
Documenting Dataset#
On top of profiling, GE also builds documentation for us.
================================================================================
Would you like to build Data Docs? [Y/n]: Y
The following Data Docs sites will be built:
- local_site: file:///home/gsajko/work/tweetfeed/great_expectations/uncommitted/data_docs/local_site/index.html
Would you like to proceed? [Y/n]: Y
Building Data Docs...
Done building Data Docs
Would you like to view your new Expectations in Data Docs? This will open a new browser window. [Y/n]: Y
This is how it will look like in Data Docs.
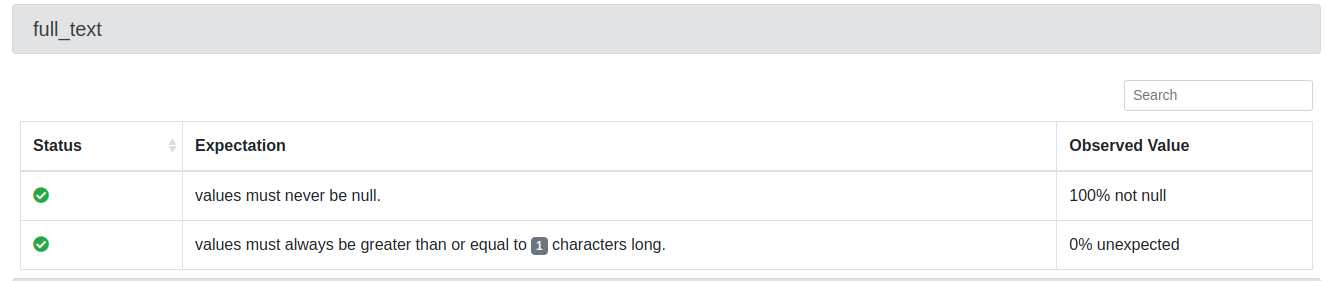
great_expectations suite edit datasetjson
this will launch disposable Jupyter Notebook, that will help you editing datasetjson suite. (oh yes, my great sense for naming things)

Above are expectations posted above in editable form in a notebook.
After that, you can view your expectations in json format.
{
"expectation_type": "expect_column_values_to_not_be_null",
"kwargs": {
"column": "full_text"
},
},
{
"expectation_type": "expect_column_value_lengths_to_be_between",
"kwargs": {
"column": "full_text",
"min_value": 1
}
Change name of a project is straight forward:
changed json file name and inside json change expectation_suite_name
"expectation_suite_name": "tweet_dataset"
create checkpoint
great_expectations checkpoint new tweets tweet_dataset
this (taken from GE docs) shows the whole process.
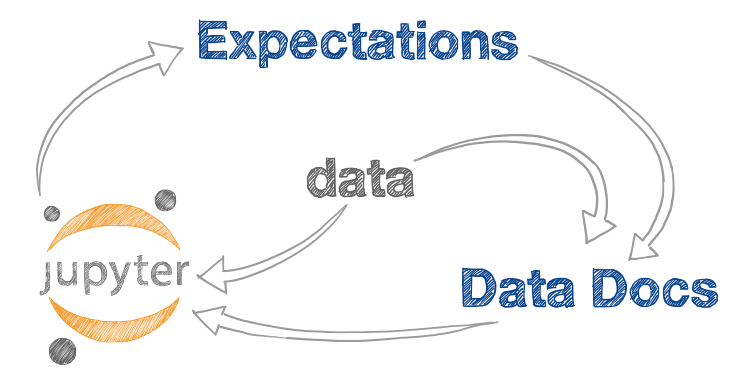
Welcome! Now that you have initialized your project, the best way to work with Great Expectations is in this iterative dev loop:
- Let Great Expectations create a (terrible) first draft suite, by running
great_expectations suite new.- View the suite here in Data Docs.
- Edit the suite in a Jupyter Notebook by running
great_expectations suite edit- Repeat Steps 2-3 until you are happy with your suite.
- Commit this suite to your source control repository.
then you can run test using:
great_expectations checkpoint run tweets
you can add this to make file
great-expectations:
@poetry run great_expectations checkpoint run tweets
@echo "The great_expectations pass! ✨ 🍰 ✨"
notice that I changed _ to - in alias.
check: great-expectations test lint style
check: great-expectations test lint style
Closing thoughts#
Let’s go back to first step of process:
Let Great Expectations create a (terrible) first draft suite, by running
great_expectations suite new.
I think this is the best thing IMHO about Great Expectations.
When you start, I’ll probably scratch your head, thinking about what exactly should you expect from your data. By creating first (terrible) draft GE removes that mental blog, and enables you to iterate to create a better and better suite.
Last modified: 22 Jul 2021