Custom twitter feed, Part 3: Displaying Tweets
Read time: 6 minutes
Displaying and reviewing tweets.#
I query tweets, I filter them out. And how to “serve” them?
Best solution would be this
In theory, this could happen, as Jack Dorsey seems to be “for it”.
But I had to look at other options in the meantime.Second, the value of social media is shifting away from content hosting and removal, and towards recommendation algorithms directing one’s attention. Unfortunately, these algorithms are typically proprietary, and one can’t choose or build alternatives. Yet.
— jack (@jack) December 11, 2019
Streamlit#
Streamlit looks like a great solution. I could grab a bigger batch, let’s say 1000 tweets, put some filters on the left sidebar, and the user could decide in “real-time” what content he is interested in (and in what his not). Or how many tweets to display:
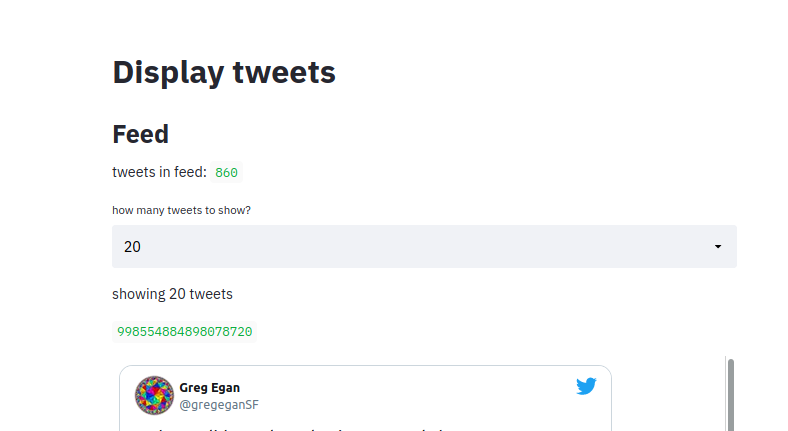
I built a simple prototype early on.
Why not streamlit?#
Fixed hight#
Your embeded-tweet-element needs to have a fixed height.
What?
It looks like this:
components.html(et, height=600, scrolling=True)
So there is an issue with this - tweets vary in content and length. If you have a media (image) or replying to someone, this means you will have a “tall” element. And you would have to have additional scrolling.
Screenshot:
 There is cut off at the bottom, and additional scrollbar on the right.
There is cut off at the bottom, and additional scrollbar on the right.
At the same time, if you post a short, one-sentence tweet, there will be a big gap.

Hard to provide feedback#
You can’t interact with tweets - if you want to reply or like, you need to open a new window in the browser. It’s a little annoying, but I can live with it.
But what if I want to label a tweet as not relevant? or put some user on the “muted” list?
There is too much friction.
I didn’t liked using it.
Tweetdeck#
What is Tweetdeck?#
https://en.wikipedia.org/wiki/TweetDeck
TweetDeck is a social media dashboard application for management of Twitter accounts.
That’s it. It is dashboard, made by Twitter, for power-users.
Drawbacks#
Tweetdeck vs Embedded tweet
Tweetdeck on the left, normal embedded tweet on the right.
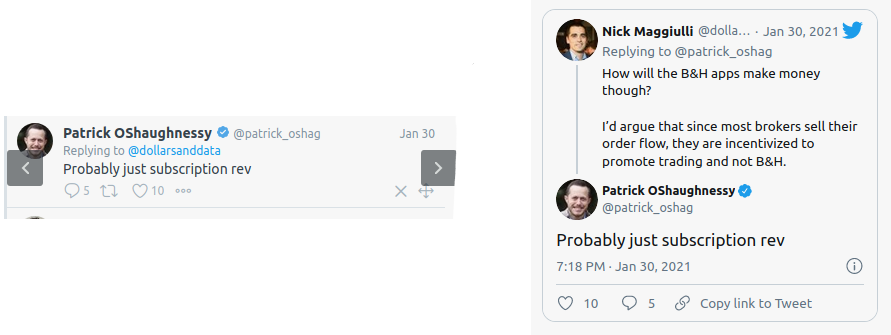
As seen above, Tweetdeck doesn’t provides full context. You don’t see tweet that user is replying to. You need to click on tweet to display it in thread.
Ugly
I don’t like the look of it. Too narrow columns makes tweets hard to read.
Doesn’t work good on mobile
But the same is true for streamlit. So I have to live with this one.
Setting up Tweetdeck#
Tweetdeck has fixed width for columns, so for better UI I use stylish plugin for firefox:
https://userstyles.org/styles/70450/tweetdeck-wide-columns?utm_campaign=stylish_stylepage
Changed code to suit me better:
.column{width:450px !important}
In Tweetdeck I have 2 most important collections:
custom_feed- where I upload tweets after filtering themnot_relevant- so I can quickly drag tweets from one column to another, to mark them as not relevant
Uploading data to collections#
I was planning to use tweepy for uploading - but it doesn’t have this functionality.
But Twitter API is quite friendly for noobs, and there is no need for using a dedicated library.
Reviewing process#
Regardless of the methods of displaying tweets, I think it is crucial to have a way of looking at the results.
It allowed me to think about new features, new ways of filtering out tweets, small fixes, etc. in an iterative matter.
The downside - this method relies on eyeballing. This could lead to silent errors. One of those examples I can think of is removing tweets that could be important for me, without me noticing.
But as my main goal is improving the signal-noise ratio, I’m willing to “loss” those tweets, if this means that my feed would be low on noise.
In precision and recall terms, I consider this a problem good for the “recall” metric.
Deleted tweets#
While writing a function that uploads tweets to a collection I noticed that sometimes upload fails. After inspection there were two reasons:
- tweet is from a protected account
- tweet is deleted
After collecting some data, almost 20% of tweets were deleted! - I guess December 2020 was a time when people regretted posting things. It changed over time - right now it’s less than 10% deleted tweets. It seems high, but I don’t think it’s surprising.
- I often delete tweets, within 10 minutes of posting (noticed spelling error or something like that; retweet something, then cancel retweet and do a quote tweet)
- there are accounts, that have automatic purge script setup, and they delete tweets older than a week or month.
This is how the output of running looks like:
972 tweets in a batch
Adding 30 tweets to collection custom-1351555076024893440
no_errors 29
not_found 1
Name: err_reason, dtype: int64
Shortened URLs#
I noticed, that despite being on the list of domains to be filtered out, some websites were still appearing in my custom feed. Upon investigation, I found the culprit: shortened url.
Here are examples:
[
'1843m.ag','4NN.cx','53eig.ht','808ne.ws','abc30.tv','abc7.la','abc7ne.ws',
'apne.ws','b-gat.es','bbc.in','bloom.bg','bos.gl','cbsn.ws','cityjourn.al',
'cnb.cx','cnet.co','cnn.it','cntrvlr.co','cos.lv','dailym.ai','econ.st',
'engt.co','hill.cm','ja.ma','jtim.es','mol.im','mtr.cool','natgeo.com',
'nyti.ms' ,'nzzl.us','on.mktw.net','on.theatln.tc','p4k.in','pewrsr.ch',
'propub.li','rdcu.be','reut.rs','rol.st','sabahdai.ly','sc.mp','slate.trib.al',
'str.sg','tcrn.ch','tdrt.io','thr.cm','ti.me','tmz.me','to.pbs.org','trib.al',
'vult.re','wapo.st','washex.am','wdrb.news','wired.trib.al','yhoo.it','zd.net'
]
Getting them was time-consuming. I had to:
- iterate over all links in my data (15k url),
- expand URL using
requests_htmlandresponse = HTMLSession().get(url)- this can take about 1 second to process- I’m using
domain = urlparse(url).netlocwhen generating custom feed, but it doesn’t handle shortened urls.
- I’m using
- there were other options for doing that but all were time-consuming. I decided on
requests_html, because it provided a easy method of getting the title of a webpage. This could be very useful later for building models - I couldconcattweet text with webpage title to provide more context for a model.
As result, I have .json file with 15k links and titles. Each item looks like this:
{
"url": "https://nyti.ms/3c4yrSX",
"title": "Could a Small Test Screen People for Covid-19? - The New York Times",
"short_url": "nyti.ms",
"long_url": "nytimes.com",
"is_news": true
}
short_url - domain extracted using urlparse(url).netloc from shortened url directly
long_url - domain extracted from url expanded by HTMLSession().get(url)
This allowed me to quickly identify additional urls I should add to my news_domains.txt file.
But there were cases, when shortened url sometimes led to a news site, and sometimes not. I decided to have a threshold of 50% - if shortened url led to a news site 50% of the time, it should be counted as a news domain.
Here are urls that were spared:
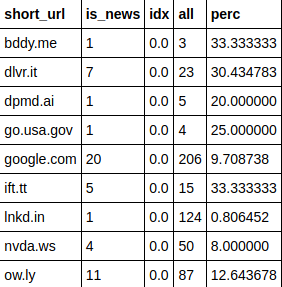
Labeling training data#
As shown here, labeling tweet as not_relevant is as simple as drag & drop from one collection to another.
 click for full resolution
click for full resolution
Right now I reviewed 11k tweets, and in my not_relevant collection I have … about 150-180 tweets.
This is due to the iterative process of reviewing:
Most of the time, before moving tweet to not_relevant I asked myself:
“Can I prevent seeing similar tweets in the future?”
So instead of adding tweets to a collection, most of the time I created a new filtering-out rule or tweaked some code.
Such a low not_relevant tweets count seen by me is a good sign. This is what I was aiming for.
On the other hand, if I like a tweet, and would like to see more of that kind of tweet in the future, I just … “like” ❤️ it.
Right now I have over 1700 liked tweets, so that should be plentiful for what’s next.
What’s next#
Tweets are getting stale - I’m no longer see low-noise tweets, but I don’t find most of them interesting right NOW.
So finally comes time for building a model.
I will frame the ranking problem as a binary classification problem, and will just sort tweets by the output of the model.
Last modified: 16 May 2021