Custom twitter feed, Part 2: Collecting and Filtering Data
Read time: 8 minutes
Collecting training data#
Collecting data#
I collect Twitter data using a library made by Simon Willison - twitter-to-sql .
My first approach was to do it by myself: Twitter API is very clear, so it shouldn’t be too hard to just grab tweets with API and dump them into SQL? Right? It wouldn’t be a problem as a one-time-thing, as I usually had done in the past in jupyter notebooks. But if I would want to make something more robust - with proper testing etc it wouldn’t be a “custom twitter feed” project but a “Twitter API to SQL” project.
So I decided to use Simon’s library. It’s awesome, I have it “git-cloned” in a folder, so from time to time I take a look at the code. It’s a part of a bigger project by Simon called Dogsheep . What is Dogsheep? From the website: “Tools for personal analytics using SQLite and Datasette”. In short - Dogsheep is for getting your personal data, and Datasette is for displaying/analyzing.
CLICK for more Datasette and Dogsheep
detailed notes by Simon:
LINK
Setting up cron jobs#
This was new to me.
So what are cron jobs? Wikipedia
: “is a time-based job scheduler”.
It means, that you schedule when you want a script to run.
For me, the script was twitter-to-sqlite command downloading my Twitter timeline, and time was “every 5 minutes”.
You put this information into a file called crontab and it executes tasks in the background.
Here are some resources I found useful for setting up cron jobs on Ubuntu:
- https://www.digitalocean.com/community/tutorials/how-to-use-cron-to-automate-tasks-ubuntu-1804
- https://www.howtogeek.com/101288/how-to-schedule-tasks-on-linux-an-introduction-to-crontab-files/
First I tried this command below, but without success.
*/1 * * * * cd /home/gsajko/work/custom_twitter_feed run-one twitter-to-sqlite home-timeline home.db --since -a auth/auth.json
I spent way too much time debugging this, looked at many log/syslog files.
Small things I have learned:
How to check if cron is working?
ps -ef | grep crond
How to look at the current crontab (without going into the editor)?
crontab -l
gsajko 16198 16000 0 10:56 pts/2 00:00:00 grep --color=auto crond
My script still didn’t run. But I found this gem :
The vast majority of “my cron script doesn’t work” problems are caused by this restrictive path. You can solve this in a couple of ways:
- Provide the full path to your command.
1 2 * * * /path/to/your/command
So I quickly remade it (removed cd part, added full paths for twitter-to-sqlite, to home.db, and to auth.json file)
2,7,12,17,22,27,32,37,42,47,52,57 * * * * run-one /home/gsajko/miniconda3/bin/twitter-to-sqlite home-timeline /home/gsajko/work/custom_twitter_feed/home.db -a /home/gsajko/work/custom_twitter_feed/auth/auth.json --since
Simon also shared his crontab for his personal data warehouse here: https://gist.github.com/simonw/1299d61d17637d1145955ebc019ea3c4.
I shamelessly copied his “time” settings.
What is the run-one? It checks if the previous run was completed, before starting a new one. Given possible timeouts on API side, it’s great to have it in place.
https://blog.dustinkirkland.com/2011/02/introducing-run-one-and-run-this-one.html
Note about collecting data#
I’m using home-timeline command. Here is info from Twitter API docs:
Up to 800 Tweets are obtainable on the home timeline. It is more volatile for users that follow many users or follow users who Tweet frequently.
If you have muted accounts, using this endpoint WON’T get their tweets. I some way, I’m giving some of the control to twitter when using this option. But I wanted to have a wide range of tweets, and another option would be to download ALL tweets by ALL users I follow.
This would balloon the database waaay more than I would like to - this option would download 3200 tweets of each user. But it would download another 3200 with next use - until it would grab all possible tweets.
I did this as a test for a list of only 60 users, and db file was about 200mb in size.
Compared to home-timeline db file from grabbing tweets from more than 600 users I follow - 160mb (about 2,5 months of cronjobs).
As I mentioned earlier - the script downloaded 3200 each time per user - going back in time to 2008 for some users. It was fun looking at tweets posted in 2008, though. People were using Twitter in a totally different way than today - there were mostly micro-blogging (“I ate lemon pie today”, “watching the game” - that kind of stuff).
Filtering out#
Finding news#
As a part of the design, my goal was to remove news from my feed. The first “filter” should remove tweets related to the news.
After pondering for some time (“Should I do ML-based news detection model?"), I arrived at a very simple solution:
- removing tweets containing links to news domains
All I needed, is a collection of news domains. Luckily for me, there is such a dataset: News Aggregator Dataset It’s a collection of headlines - over 400k news stories.
In that dataset, there is a column named HOSTNAME, so I could take unique values from that column and ignore the rest of the dataset.
This got me over 9000 unique news domain names.
Get the domain from the tweets#
so let’s move back to tweets.
To find news in tweet’s urls I needed to clean them up.
- remove links to other tweets (they are urls - but not )
- remove short links, like “bit.ly”, “buff.ly”. (in hindsight - I’ll leave them for extracting domains)
Then I needed a function to find url in tweet (simple regex re.findall(r"http\\S+", tweet))
to get the domain I used urllib library:
After reviewing some batches, I noticed that some domains weren’t detected properly, so there was a need for some splitting and joining - results were transformed to match the news_domain_list
def get_domain(url: str) -> str:
"""extracts domain from url, returns it"""
domain = urlparse(url).netloc.replace("www.", "")
dot_split = domain.split(".")
if (len(dot_split) > 2) & (
dot_split[-1] == "com"
): # for links like "edition.cnn.com", but not like "site.co.nz"
return ".".join(dot_split[1:])
else:
return domain
Is it news?#
The result of this was a single pandas cell with a list.
Current record holder (with 5 links):
Improving the Fairness of Deep Generative Models without Retraining
— AK (@ak92501) December 10, 2020
pdf: https://t.co/ZhJ5CoRYVk
abs: https://t.co/oxVwuYh1zK
project page: https://t.co/1EgwOvlfJ7
github: https://t.co/T0xFCofJTo
colab: https://t.co/rdaREilt2S pic.twitter.com/di8b0Kz0I0
I expanded pd.DataFrame, so each domain has its own column.
On each of those columns I used simple .isin
for col in columns:
df[col] = df[col].isin(news_domains_list)
Then I summed it up in one column contains_news and made values 0 or 1.
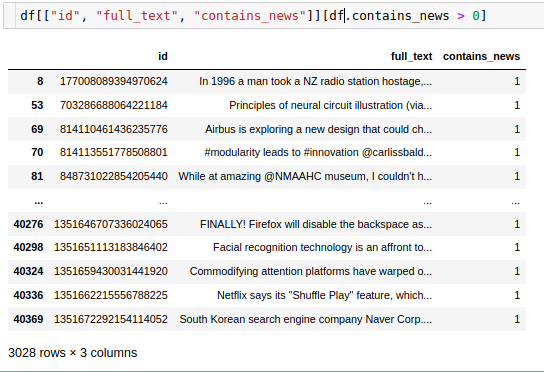
Through uploading batches of tweets to the collection and reviewing them, I make some changes to that list:
- removed some domains (youtube.com, linkedin.com),
- noticed that some of the domains weren’t in the dataset (e. g. techmeme.com, buzzfeednews.com), so I added them to the list.
On top of that - I saw that often quote tweets were containing news, or someone was replying to the news posted by another person.
To deal with that, I decided to add tweet + quoted_tweet + in_reply_to and use find_news function on that text.
Muting stuff#
Another rule-based solution - just mute words and accounts. The Twitter solution doesn’t work for me - it works ok with accounts, but somewhat muting words was unreliable in my experience.
Muted words#
It’s very simple: I have two simple lists, one is for case-sensitive words. Example looks like this:
mute_list = ["breaking:", "🍿", "🚨", "san francisco"]
mute_list_case_sensitive = ["GOP", "BREAKING", "MAGA"]
I just remove tweets with those strings in them.
Muted accounts#
I created a special list on Twitter called muted. If I decide I don’t want to see a particular person in my feed I add them to that list.
I found also a blocklist - made of a New York Times journalist. I don’t have anything against this particular magazine, but as I want to reduce the amount of news-related stories this was useful.
Twitter's API makes us ask for all these permissions. All the app does is block these accounts: https://t.co/TaVranhx9k. You can uninstall the app right after using it. The accounts will stay blocked.
— Block the New York Times (@blocknyt) February 8, 2021
See the right-hand side of the screenshot.
I didn’t want to block them - so I downloaded that list, and using API added 900 accounts to the list nytblock.
Be careful while doing that, Twitter doesn’t like too much activity when it comes to lists, their requests limit is lower for that.
From docs
:
Please note that there can be issues with lists that rapidly remove and add memberships. Take care when using these methods such that you are not too rapidly switching between removals and adds on the same list.
I was hitting Rate Limit Error all the time. It took me some time to realize, it was due to my while... loop.
Also, be careful with using a loop and using functionality that e.g. involves tweets/likes - I deleted once my whole feed while playing with API.
With two lists in place, I created a simple function that grabs users from the list, and I use this to filter out those users. I try where I can incorporate existing functionality in Twitter so that not everything is local on my PC.
Next#
Reviewing and labeling batches - displaying newsfeed.
Last modified: 16 May 2021