How to research stuff using Twitter
Read time: 3 minutes
Key to this method - follow lots of opinionated people.#
I follow many people - more than 600. There are many ML experts. So if I’m researching what methods to use, what algorithms, or just want to learn about a subject I’ll use Twitter first for that.
Using search#
Let’s say I want to learn how to do “topic modeling” on a dataset made of tweets. I just use search, remembering to check “People you follow”
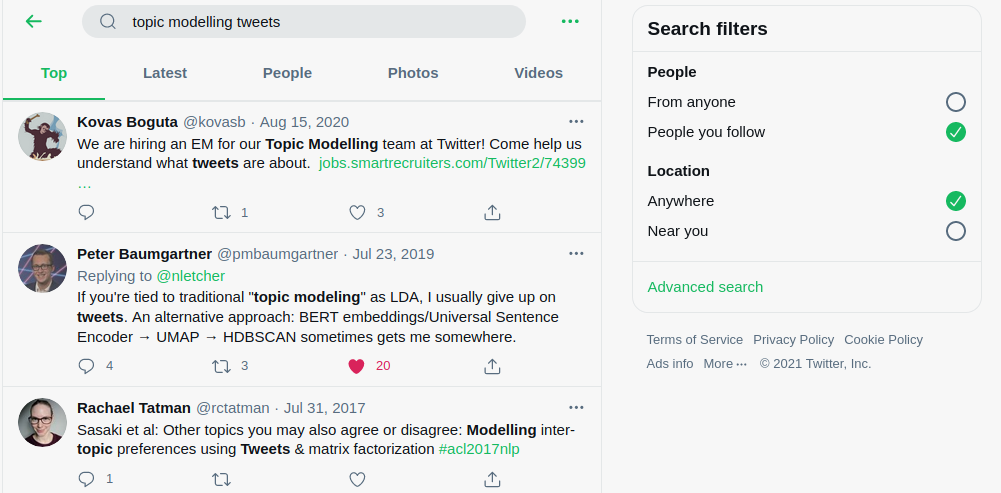
I especially liked this tweet:
If you're tied to traditional "topic modeling" as LDA, I usually give up on tweets. An alternative approach: BERT embeddings/Universal Sentence Encoder → UMAP → HDBSCAN sometimes gets me somewhere.
— Peter Baumgartner (@pmbaumgartner) July 23, 2019
Without any prior knowledge, just from that one tweet by @pmbaumgartner , you can learn that there is a traditional topic modeling method called “LDA”, and it doesn’t provide good results for tweets. “BERT embeddings/Universal Sentence Encoder → UMAP → HDBSCAN” seem to work better.
But let’s look at the whole discussion.
Treeverse#
I go to the “main” tweet and use a browser plugin called Treeverse
This is the tweet that started the whole discussion.
Hey #NLProc folks, do you have any tips for doing topic modelling on Twitter text? The main trick I see coming up in the papers I've found is concatenating tweets together by hashtag (or other means) to handle the short document problem. Any other tricks?
— Ned Letcher (@nletcher) July 23, 2019
Treeverse gives me a good overview - Twitter sometimes hides some tweets, so I prefer to use Treeverse.
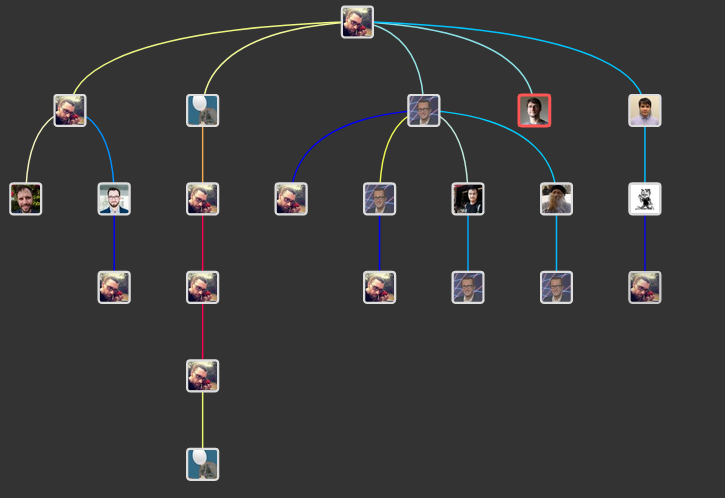
One other tweet contained tricks on how to improve the performance of modeling:
Concatenate by user, or by time (days, hours). Concat quote tweets. Maybe replies also.
— Igor Brigadir (@IgorBrigadir) July 23, 2019
Keep original + copy of Embiggened tweet: replace @ with names, split #multiwordhashtags (GATE has an implementation). Replace URLs with page title or card meta tag.
Try NMF topic models!
There was also a response by this guy:
You can densify your matrix by doing diffusion over the column space under word-vector similarity.
— Leland McInnes (@leland_mcinnes) July 23, 2019
Remember “BERT embeddings/Universal Sentence Encoder → UMAP → HDBSCAN” from the previous tweet?

Leland happens to be the researcher behind UMAP and HDBSCAN.
Instant “follow” for me.
Ok, so what about LDA? What do other people think about it? I repeated the search, remembering to check “People you follow”.
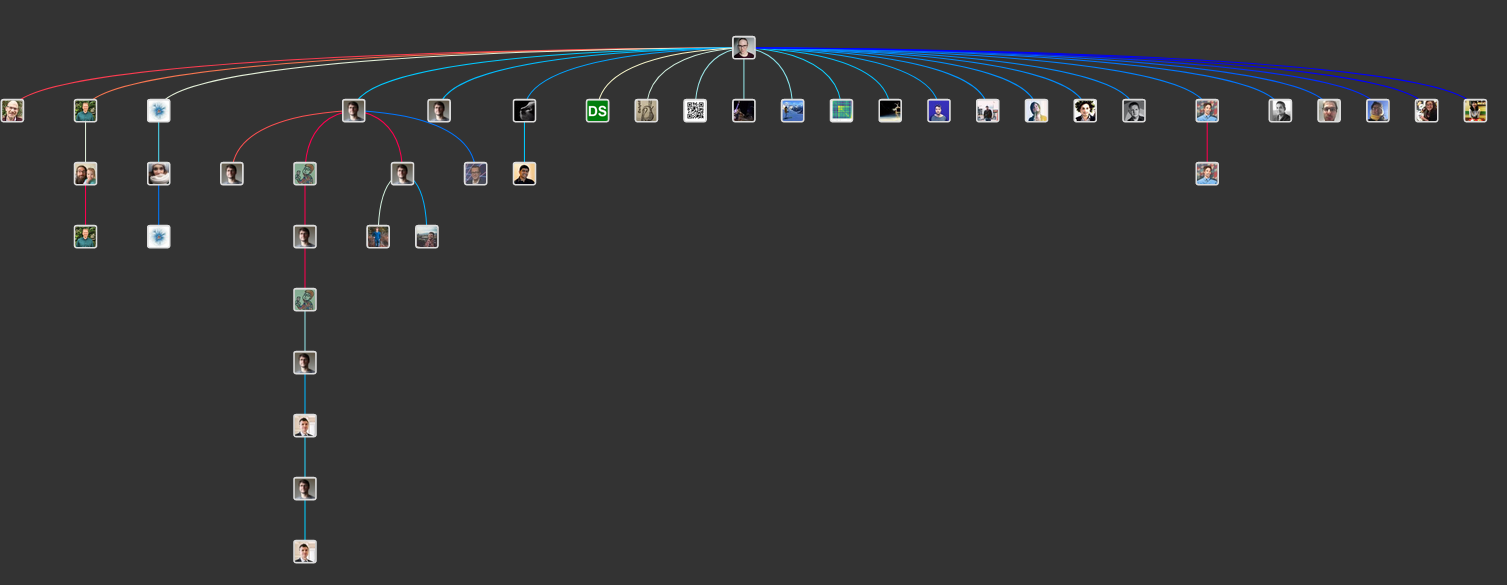
This time I needed to dig a little deeper, focused on this tweet:
What are y'alls current favorite unsupervised classification/clustering approaches for text? So far I've looked at:
— Rachael Tatman (@rctatman) May 29, 2019
🔡 LDA
🔡 Embeddings (doc2vec) + clustering (k-means
🔡 Unsupervised keyword extraction (YAKE)
Is there something else I should consider? 🤔📝
The tree got way bigger (Rachael has 22k followers)
But if you zoom in:
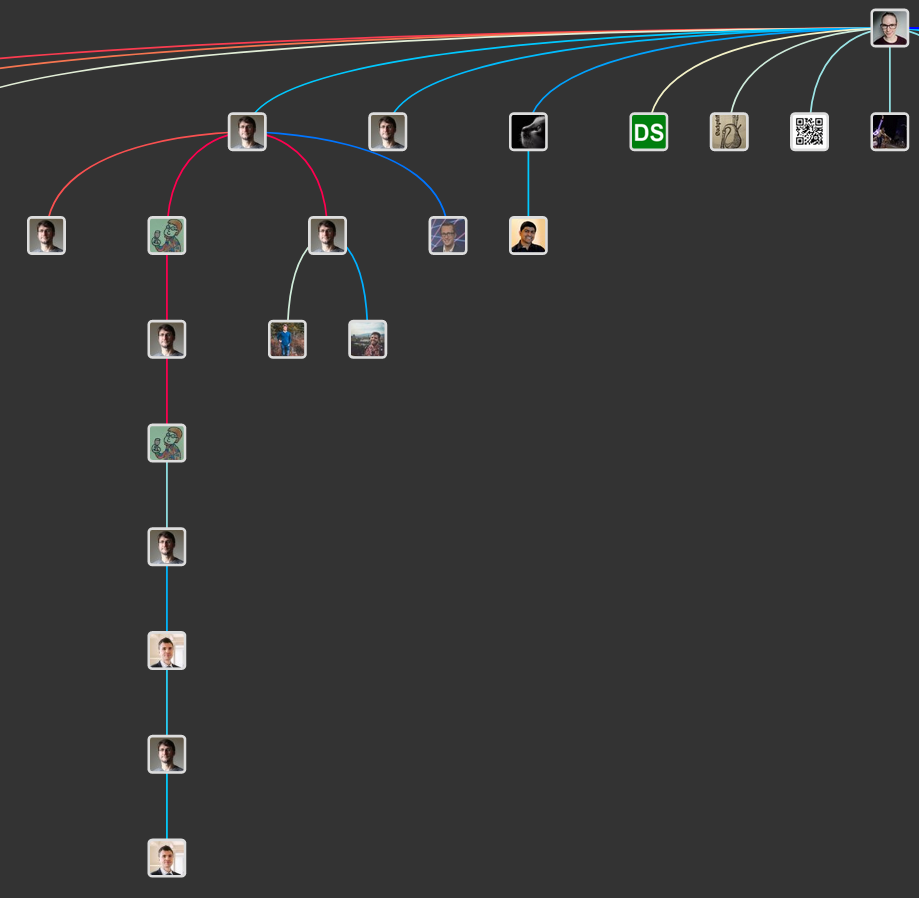
We see familiar faces (@pmbaumgartner , leland_mcinnes )
Leland even provides code examples for his approach.
Here's a very quick example: https://t.co/Bu7LLeG11C
— Leland McInnes (@leland_mcinnes) May 30, 2019
Not anything major, but hopefully good enough for a very quick/naive approach to demonstrate the possibilities.
https://gist.github.com/lmcinnes/fbb63592b3225678390f08e50eda2b61
Twitter is good for finding different approaches/methods, way better than any other forum-like solution.
But the key is following correct people.
And do bias to the side of following more opinionated folks.
Last modified: 2 Mar 2021